Version 1.0 — Published May 2026
Quick Answer
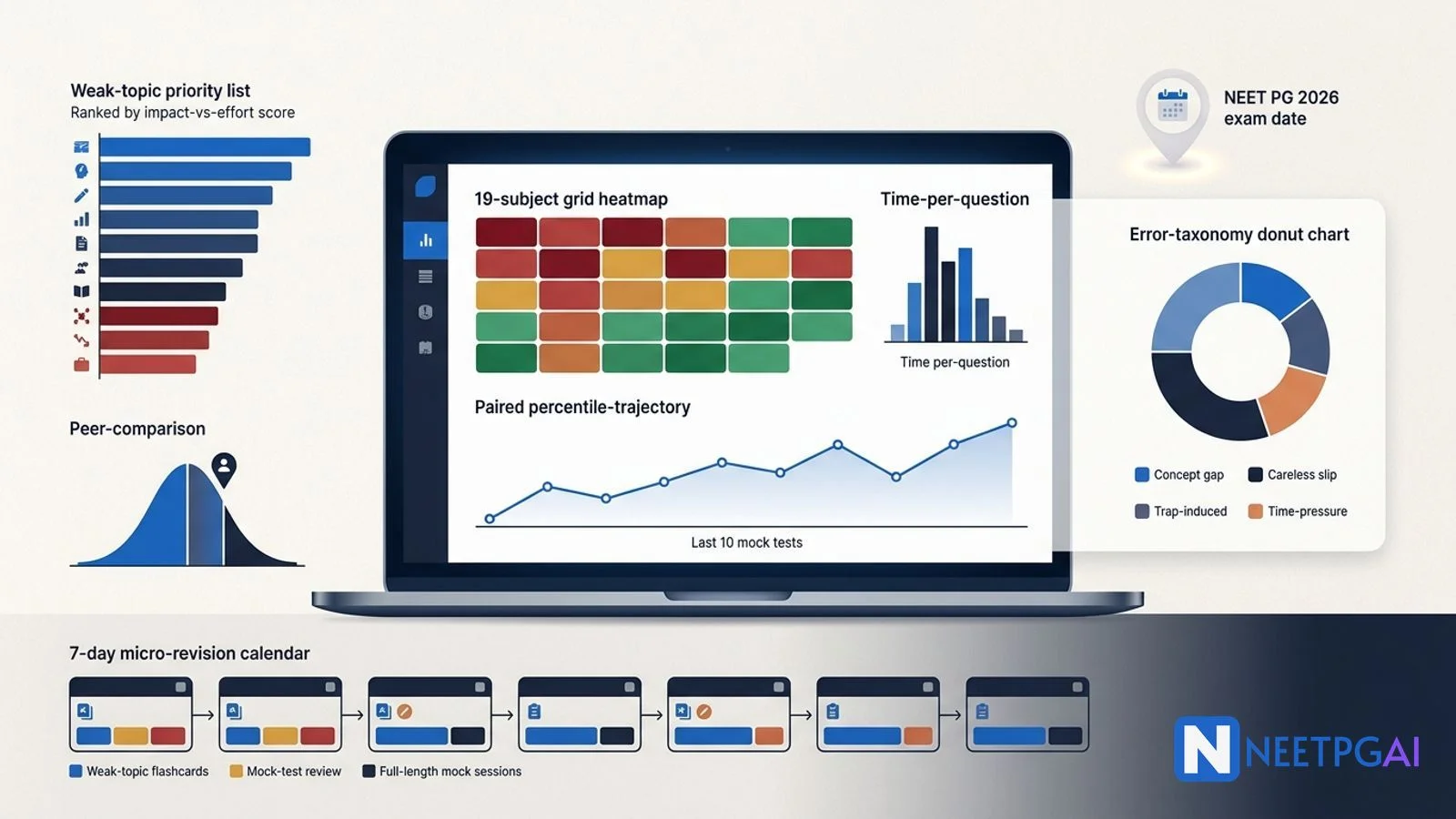
A typical NEET PG mock test yields approximately 70-110 wrong or skipped answers across 180 questions (the revised NEET PG 2026 pattern). Reading the analytics layer-by-layer surfaces 8-12 actionable weak spots that, if addressed in the next 7-10 days, can move your score by 15-30 marks. Decoding one mock fully is worth three mocks half-decoded. Use this 12-lens reading protocol:
- Subject-wise accuracy trends — surface-layer triage; identify the 3-4 weakest subjects
- Time per question by subject — surgical efficiency; flag subjects with over 70 sec per question (slow) or under 30 sec (rushed)
- Topic-level weakness — actionable layer; red/amber/green heatmap of topic cells
- Question-type analysis — single best answer vs assertion-reason vs image-based vs case-based; identify the format you struggle with
- First-attempt vs review accuracy — measures impulsive answering and second-guessing
- Percentile vs marks — percentile is more reliable than raw marks; track trajectory
- Confidence vs accuracy calibration — Sure-and-wrong is the most dangerous cell
- Subject-specific timing red flags — Anatomy and Pathology slower, PSM and Pharmacology faster
- Pattern analysis of wrong answers — option-position bias, NOT/EXCEPT misses, look-alike traps
- Adaptive next-step practice — NEETPGAI auto-generates focused practice from weakest cells
- Know when to stop solving and start reviewing — typically after 6-8 mocks
- Last-month vs 3-months-out interpretation differ — interpretation layer changes over the timeline
Why decoding analytics beats re-taking mocks
The marginal value of an additional mock test drops sharply after 6-8 full-length mocks. Beyond that point, the test-taking experience itself adds little — you already know the timing, the format, the fatigue curve. What adds value is the diagnostic information from the mocks you have already taken. A typical 180-question mock (matching the NEET PG 2026 pattern) yields ~70-110 wrong or skipped answers; reading the analytics layer-by-layer surfaces 8-12 actionable weak spots that, if addressed in 7-10 days, move your score by 15-30 marks.
Re-taking another mock without first decoding the previous one is the single most common mistake in the last 60 days — it consumes 3.5 hours of solving plus 2-3 hours of review without revealing new weak spots because you have not closed the loop on the previous mock.
Compounding rule: 1 mock fully decoded = 3 mocks half-decoded for marks-per-hour return.
Lens 1: Subject-wise accuracy trends — the surface layer
The first chart most platforms show is a bar chart of accuracy by subject. Sort subjects from lowest to highest accuracy. Identify the 3-4 weakest subjects.
| Subject | Mock 1 | Mock 2 | Mock 3 | Trend |
|---|
| Anatomy | 58 percent | 62 percent | 66 percent | Rising |
| Physiology | 71 percent | 73 percent | 75 percent | Rising slow |
| Pathology | 68 percent | 64 percent | 60 percent | Falling — red flag |
| Pharmacology | 72 percent | 75 percent | 78 percent | Rising |
| Medicine | 55 percent | 56 percent | 55 percent | Flat — red flag |
| Surgery | 64 percent | 68 percent | 72 percent | Rising |
| OBG | 70 percent | 72 percent | 74 percent | Rising slow |
| Pediatrics | 76 percent | 78 percent | 80 percent | Rising |
| PSM | 82 percent | 84 percent | 85 percent | Strong |
| Forensic Medicine | 65 percent | 70 percent | 75 percent | Rising fast |
Interpretation:
- Rising subjects — current strategy working; reinforce with topic-level revision
- Flat subjects — current strategy stuck; needs new approach (new resource, different question bank, change of teacher)
- Falling subjects — overlooked; reschedule revision; usually indicates either neglect or that easier early-mock questions masked weakness
Limitation: Subject-wise accuracy is too coarse to drive remediation. Telling yourself "study more Medicine" wastes hours. Drop to topic-level (Lens 3).
Lens 2: Time per question by subject — surgical efficiency
Mock tests give you ~70 seconds per question (180 questions in 210 minutes = 70 sec/Q average, matching the revised NEET PG 2026 pattern). Subjects with heavy diagrams and long stems (Surgery operative cases, Pediatrics neonatology, OBG management) consume more time; quick-recall subjects (PSM, Pharmacology, Forensic Medicine) consume less.
Section-locked reality (NEET PG 2026): the exam is now delivered as 5 sections (Group A–E), 36 questions each, with a fixed 42-minute timer per section. Each section locks permanently when its 42-minute timer expires — you cannot return to a previous section or jump ahead, and "Mark for Review" only works within the active section. Time your mocks in the same 42-min-per-36-questions blocks, and read your time-per-question analytics against this constraint: a subject that runs slow can no longer be "finished later" from a leftover pool at the end of the paper.
| Subject | Optimal sec/Q | Actual sec/Q | Status |
|---|
| Anatomy | 50 | 65 | Slow — concept gap |
| Physiology | 50 | 48 | Optimal |
| Pathology | 55 | 75 | Very slow — second-guessing |
| Pharmacology | 40 | 35 | Optimal |
| Medicine | 60 | 90 | Very slow — confidence gap |
| Surgery | 55 | 62 | Slightly slow |
| OBG | 55 | 50 | Optimal |
| Pediatrics | 55 | 55 | Optimal |
| PSM | 40 | 30 | Too fast — rushed |
| Forensic Medicine | 35 | 35 | Optimal |
Two red flags:
- Slow subjects (over 70 sec/Q) — usually indicate concept gaps; flag for topic-level drill-down
- Rushed subjects (under 30 sec/Q) — usually indicate over-confidence; cross-check accuracy on these subjects; PSM is the classic over-confidence subject
Action: target slow subjects with concept revision; target rushed subjects with accuracy review (often the rushed subjects have hidden accuracy drop of 5-10 percent that the headline number masks).
Lens 3: Topic-level weakness — the actionable layer
This is where decoding pays off. Drop from subject to topic. NEETPGAI displays a colour-coded heatmap.
| Subject | Strong topic cells (over 75 percent) | Borderline (50-75 percent) | Weak (under 50 percent) |
|---|
| Pathology | Cardiac, Endocrine | Haematology, GI | Renal, Liver, Neoplasia |
| Medicine | Cardiology, Endocrinology | GI, Respiratory | Nephrology, Haematology, Rheumatology |
| Surgery | General, Vascular | Urology, Plastics | Hepatobiliary, Paediatric surgery |
| OBG | Antenatal, Labour | Gynaec endocrine | Infertility, Gynaec oncology |
Interpretation:
- Each weak topic cell typically contributes 3-6 questions per mock — that is 12-24 marks at the cell level
- Top-10 weak cells contribute approximately 30-60 marks per mock collectively
- Spending 1-2 days on each top-10 cell over 2-3 weeks moves these cells from under 50 percent to 70+ percent — yielding 20-40 marks improvement
NEETPGAI auto-clusters cells into red (under 40 percent), amber (40-60 percent), and green (over 60 percent) and ranks them by total mark contribution so you can prioritise the highest-yield weak spots first.
Lens 4: Question-type analysis — format weakness
Modern NEET PG papers include 4-5 question types. Track accuracy by type.
| Question type | Accuracy | Comment |
|---|
| Single best answer (SBA) — straightforward recall | 72 percent | Mainstay; should be highest |
| Clinical vignette case-based | 68 percent | Tests application; revise common cases |
| Assertion-Reason (A-R) | 58 percent | Format weakness — needs targeted practice |
| Image-based MCQ | 60 percent | Format weakness — drill image PYQs |
| Match-the-following / sequence | 70 percent | Acceptable |
| NOT / EXCEPT (negative stem) | 55 percent | Comprehension trap — practice underlining NOT |
Action: the format with the lowest accuracy is often a learned bias not a knowledge gap. 30-50 targeted practice questions in that format restores 5-10 percent accuracy.
Lens 5: First-attempt vs review accuracy
Some students answer a question, mark it for review, and change the answer in the second pass — sometimes for the better, sometimes for the worse.
| Pattern | First-attempt correct | After review | Net |
|---|
| Changed wrong to right | 22 | After review: 35 (gained 13) | +13 |
| Changed right to wrong | 18 (after review: 9) | Lost 9 | -9 |
| Net review benefit | +4 | | Slight positive |
Interpretation:
- A net positive indicates productive reviewing; continue
- A net negative indicates destructive second-guessing; reduce marking for review; trust the first instinct
- The all-time worst pattern — changing high-confidence right answers to wrong answers under last-10-minute panic. NEETPGAI flags this on the analytics dashboard
Heuristic: "Never change your first answer unless you have positive new evidence (e.g., a recall trigger from another question on the paper). Doubt alone is not enough."
Lens 6: Percentile vs marks — trajectory matters more than score
Raw marks vary by mock difficulty. Percentile normalises.
| Mock | Marks/720 | Percentile vs platform cohort | All-India rank projection |
|---|
| Mock 1 (early) | 480 | 62nd | ~25,000 |
| Mock 2 | 510 | 68th | ~18,000 |
| Mock 3 | 525 | 73rd | ~12,000 |
| Mock 4 | 540 | 78th | ~8,500 |
| Mock 5 | 555 | 82nd | ~6,000 |
| Mock 6 | 565 | 85th | ~4,500 |
| Mock 7 (target) | 580 | 88th | ~3,000 |
| Mock 8 (target) | 595 | 91st | ~2,000 |
Interpretation:
- Rising trajectory (62 to 85 over 6 mocks) — strong; on track for top-5000 rank
- Flat trajectory (62 to 65 over 6 mocks) — strategy stuck; revise approach
- Falling trajectory (62 to 55) — usually burnout or poor health; rest and reset
Indian context (2025 cycle):
- 99.7th percentile → AIIMS-Delhi-equivalent / top INI-CET seat
- 99.5th percentile → PGIMER MD aspirant
- 98-99th percentile → top state govt MD seat
- 95-97th percentile → mid-tier state govt MD seat
- 90-94th percentile → DNB / state govt diploma / state private MD
Lens 7: Confidence vs accuracy calibration — Sure-and-wrong is the danger zone
Tag each answer as Sure / Doubtful / Guessed. The confidence matrix reveals 4 cells.
| Correct | Wrong |
|---|
| Sure | Sure-and-correct (target over 90 percent) | Sure-and-wrong (target under 5 percent) |
| Doubtful | Doubtful-and-correct | Doubtful-and-wrong |
| Guessed | Guessed-and-correct (random hits) | Guessed-and-wrong |
Interpretation:
- Sure-and-correct — your concept knowledge is solid; minimal revision
- Sure-and-wrong — the most dangerous pattern; you confidently held a wrong belief; demands concept rewriting from primary sources
- Doubtful-and-correct — you knew enough to guess right; flashcard these to convert to Sure-and-correct
- Guessed-and-correct — chance; do not bank on these; treat as concept gaps for next mock
Calibration targets:
- Well-calibrated student: Sure-and-wrong under 5 percent
- Over-confident student: Sure-and-wrong 15-25 percent (high risk of exam-day errors)
- Under-confident student: Doubtful-and-correct over 30 percent (anxiety masking knowledge; flashcards convert these)
NEETPGAI auto-flags Sure-and-wrong questions as "priority concept rewrites" on the analytics dashboard.
Lens 8: Subject-specific timing red flags
Some subjects have natural timing characteristics. Deviations signal trouble.
| Subject | Typical sec/Q | Red flag |
|---|
| Anatomy | 50-55 | Over 70 means concept gap |
| Pathology | 55-60 | Over 75 means second-guessing |
| Pharmacology | 35-45 | Over 60 means recall gap; under 25 means rushed |
| Medicine | 55-65 | Over 80 means clinical judgement gap |
| Surgery | 55-65 | Over 80 means operative-case unfamiliar |
| OBG | 50-60 | Over 75 means management-decision uncertain |
| Pediatrics | 50-60 | Over 75 means dose / milestone uncertain |
| PSM | 35-45 | Under 25 means rushed (PSM is the classic over-confidence subject) |
| Forensic Medicine | 30-40 | Over 50 means section-number confusion |
Lens 9: Patterns in incorrect answers — positional bias and trap families
Track the option position of correct answers in your wrong responses. Is there a bias? AI-generated MCQs in older banks were positionally biased toward option A (45 percent A, 34 percent B, 14 percent C, 7 percent D in pre-shuffle audits) — NEETPGAI's question bank now shuffles options uniformly to defeat this, but legacy banks may not.
| Pattern | Sign | Remediation |
|---|
| Skew toward option A | Likely working with an older / unfixed question bank | Switch to NEETPGAI shuffled bank |
| NOT / EXCEPT misses | You overlook the negative stem | Underline NOT/EXCEPT in every question stem; practice 30-50 EXCEPT questions |
| "All of the above" misses | You stop reading after finding one right option | Read all 4 options before answering |
| Look-alike distractors (one right answer surrounded by 3 plausible variations) | Concept confusion | Practice "compare-and-contrast" flashcards |
| Obsolete framework distractors (DSM-IV, ICD-10 in DSM-5-tested questions) | Out-of-date textbook | Use updated source for the topic |
Lens 10: Adaptive next-step practice — NEETPGAI as the implementation layer
The hardest part of mock analytics is the "now what?" step. NEETPGAI automates this.
- Auto-generated focused practice queue from your top-10 weak topic cells; 15-25 questions per cell drawn from the question bank and PYQs
- Auto-generated flashcards from your Sure-and-wrong list with the correct concept rewritten
- Spaced repetition schedule (1d / 3d / 7d / 14d / 30d) attached to each new flashcard
- Leech card alert for any flashcard failed 3 or more times — needs rewriting or deletion
- Weekly mock-test recommendation based on your current weakest cells (so the next mock challenges your weak spots rather than your strengths)
- Mode —
/practice?mode=pyq&year=2025&subjectId=N pre-selects the PYQ mode with year and subject filter; useful for drilling year-specific PYQs
The principle is close-the-loop — every mock analysis must end in a concrete practice queue and a flashcard set, not a vague resolution to "study more".
Lens 11: When to stop solving mocks and start reviewing
There is a transition point in your prep timeline where the value of additional mocks drops below the value of deep review. Signs you have reached it:
- You have completed 6-8 full-length mocks
- Your percentile trajectory has plateaued for 3 consecutive mocks
- Your time per question is within optimal range across most subjects
- Sure-and-wrong is under 8 percent
- You can predict your mock score within ±20 marks before solving (indicating predictability of performance)
At this point, the marginal value of an additional mock is small. Switch to deep review:
- 60-70 percent on weakest topic cells (focused practice + flashcards)
- 20-30 percent on Sure-and-wrong concept rewrites
- 10-20 percent on full-length untimed practice sessions (not full mocks) to consolidate
Re-introduce one mock every 7-10 days to recalibrate.
Lens 12: Last-month vs 3-months-out interpretation
The same mock analytics dashboard reads differently depending on time-to-exam.
3 months out — wide-angle interpretation:
- Subject-level patterns dominate; topic-level still emerging
- Spend 60-70 percent on broad concept revision and 30-40 percent on weak topics
- Tolerable to spend 1-2 hours on each weak topic with primary source revision (Harrison, Robbins, Bailey & Love)
- Run 1 mock per week
- New topics can still be started
6 weeks out — narrow-angle interpretation:
- Topic-level dominates; identify top-10 weak cells contributing most to lost marks
- 40-50 percent on these weak cells, 30 percent on consolidation, 20 percent on mocks
- Run 1-2 mocks per week
- No new broad topics; only finishing existing ones
Last month — surgical interpretation:
- Stop broad revision
- Focus entirely on (1) Sure-and-wrong concept rewrites, (2) leech-card review, (3) top-5 weak topic cells, (4) mistake-bank flashcards
- No new topics
- Run 1 mock per week; spend 2-3 hours per mock on analysis
- 60-90 minutes daily on flashcards
Last week — confidence consolidation only:
- Review only the 100-150 highest-yield trap cards and known-confident cards
- No new mocks
- Sleep, hydration, mental rehearsal of exam-day routine
- 60 min max daily review
Last 24 hours — only confidence cards:
- 20-30 min of "confidence card" review (the cards you know cold) for neural priming
- No new content
- Confirm exam-day logistics (admit card, ID, route, food)
- Sleep 7-8 hours
Neurocognitive rationale: New memories take 24-72 hours to consolidate; anything learned in the last week is unreliable under exam stress. Cohort data shows last-month strategic interpretation adds 15-30 marks vs students who keep doing more mocks.
A worked example — decoding Mock 5 in 90 minutes
Here is how a topper aspirant might decode a specific mock test.
Mock 5 result: 555/720; 88th percentile.
Step 1 (10 min) — Lens 1 + 2: Subject scan. Falling subjects — Pathology (60 percent), Medicine (55 percent), OBG (57 percent). Slow subjects — Pathology (75 sec/Q), Medicine (90 sec/Q). Action: target these 3 first.
Step 2 (20 min) — Lens 3 + 4: Topic drill-down. Top weak cells — Renal pathology (38 percent), Nephrology in Medicine (40 percent), Gynae oncology (42 percent), Liver pathology (44 percent). Question type weakness — Assertion-Reason (55 percent), NOT/EXCEPT (52 percent).
Step 3 (15 min) — Lens 5 + 6 + 7: Review pattern audit. Net review benefit -3 (destructive second-guessing). Sure-and-wrong rate 12 percent (too high). Percentile 88th — on track but plateauing.
Step 4 (10 min) — Lens 8 + 9: Timing red flags — Medicine and Pathology over 75 sec/Q; PSM rushed at 28 sec/Q (cross-check accuracy: 78 percent — slipping). NOT/EXCEPT pattern misses 8 of 12 — clear comprehension trap.
Step 5 (20 min) — Lens 10: Generate NEETPGAI adaptive practice queue. 25 questions each for Renal pathology, Nephrology, Gynae oncology, Liver pathology, Assertion-Reason format, NOT/EXCEPT format. Total 150 questions to drill over next 5 days.
Step 6 (10 min) — Lens 11 + 12: Decide review-vs-mock. With 6 weeks left, stay narrow-angle. Allocate next 5 days to focused practice queue + Sure-and-wrong flashcards; re-mock in 7 days.
Step 7 (5 min) — Documentation: Add 25 Sure-and-wrong concept rewrites to flashcard system. Set spaced repetition. Note "underline NOT/EXCEPT" as exam-day reminder.
Total decoding time: 90 minutes. Yields ~20-25 marks improvement in the next 2-3 mocks if executed.
Key takeaways
- Decoding 1 mock fully is worth 3 mocks half-decoded for marks-per-hour return
- 12 lenses to read every mock analytics report
- Subject-level is too coarse; drop to topic-level for actionable insight
- Time per question reveals concept gaps (slow) and over-confidence (rushed)
- Sure-and-wrong is the most dangerous calibration cell; target under 5 percent
- Percentile trajectory matters more than raw marks
- Net review benefit must be positive; avoid destructive second-guessing
- Watch for option-position bias and NOT/EXCEPT misses
- NEETPGAI auto-generates adaptive practice queue and flashcards from weakest cells
- Stop adding mocks after 6-8; switch to deep review
- Last-month and 3-months-out interpretation differ fundamentally
- Last week is confidence consolidation only — no new content
Frequently Asked Questions
Why is reading mock test analytics more important than re-taking another mock test?
The marginal value of an additional mock test drops sharply once you have completed 6-8 full-length mocks. Beyond that point, the test-taking experience itself adds little — you already know the timing, the format, and the fatigue curve. What adds value is the diagnostic information from the mocks you have already taken. A typical 180-question mock test (matching the NEET PG 2026 pattern) yields approximately 70-110 wrong or skipped answers; reading the analytics layer-by-layer surfaces 8-12 actionable weak spots that, if addressed in the next 7-10 days, can move your score by 15-30 marks. Re-taking another mock without first decoding the previous one is the single most common mistake in the last 60 days — it consumes 3.5 hours of solving plus 2-3 hours of review without revealing new weak spots because you have not closed the loop on the previous mock. The compounding rule is simple: 1 mock fully decoded = 3 mocks half-decoded for marks-per-hour return.
What is the difference between subject-level and topic-level accuracy and which is more actionable?
Subject-level accuracy (e.g., 'Pathology 65 percent, Pharmacology 58 percent') is the surface-layer metric every mock report shows. It is useful for very broad triage but is too coarse to drive remediation — telling you 'study more Pathology' wastes hours. Topic-level accuracy (e.g., 'Cardiac pathology 78 percent, Renal pathology 42 percent, Haematology 71 percent') is the actionable metric. It pinpoints the 20-30 specific topic cells where you actually lose marks, allowing you to target 1-2 days of focused revision per cell. Most mock test platforms (including NEETPGAI) display both subject and topic accuracy; cohort data shows students who study at the topic level move accuracy 20-30 percent faster than those who stay at the subject level. NEETPGAI's topic-level heatmap auto-clusters topic cells into red (under 40 percent), amber (40-60 percent), and green (over 60 percent) and ranks them by total mark contribution so you can prioritise the highest-yield weak spots first. The principle is simple — the finer the granularity of the metric, the higher the actionable yield per hour spent on it.
How do you interpret confidence vs accuracy calibration in mock test analytics?
Confidence calibration measures how well your self-rated confidence on each question matches your actual accuracy. Some platforms (NEETPGAI included) let you tag each answer as Sure / Doubtful / Guessed. The calibration matrix reveals 4 patterns. (1) Sure-and-correct (target 90+ percent in this cell) — your concept knowledge is solid; minimal revision needed. (2) Sure-and-wrong — the most dangerous pattern; you confidently held a wrong belief; needs concept rewriting from primary sources. (3) Doubtful-and-correct — you knew enough to guess right; build flashcards to convert these to Sure-and-correct. (4) Guessed-and-correct — chance hits; do not bank on these; treat as gaps for next mock. The cell to watch most closely is Sure-and-wrong. A well-calibrated student has under 5 percent Sure-and-wrong; an over-confident student has 15-25 percent in this cell and is at high risk of compounding errors on exam day. NEETPGAI auto-flags Sure-and-wrong questions as 'priority concept rewrites' on the analytics dashboard. Calibrating across 4-6 mocks moves over-confident students to 5-8 percent Sure-and-wrong over 30 days.
How does percentile relate to marks in NEET PG and why is percentile a more reliable indicator?
Marks in mock tests vary by mock difficulty — a 540/720 score on a hard mock may be equivalent to a 600/720 on an easy mock. Percentile (your rank divided by total candidates, expressed as percentage) normalises across mock difficulty and across the cohort you compete against. A consistent 90th-percentile finish across 4-6 mocks indicates a top-1000 to top-3000 All-India rank trajectory, irrespective of the raw marks. Most platforms display both — track percentile as the primary metric and use marks only to compare similar-difficulty mocks. NEETPGAI shows percentile against the platform cohort (the closest proxy to the actual NEET PG cohort once 50,000+ aspirants are on it) and a trajectory line of percentile-vs-time across mocks. The trajectory is the most predictive single metric — a rising trajectory (60 to 70 to 78 to 84) over 6 mocks indicates 30-60 rank improvement per week and a high-confidence top-rank trajectory; a flat or falling trajectory needs an honest conversation with yourself about study strategy. The 2025 NEET PG cut-off for AIIMS-Delhi-equivalent ranks was approximately the 99.7th percentile; PGIMER MBBS-aspirant cut-off approximately 99.5th; standard MD seat at top state colleges approximately 98th-99th.
What is the difference between last-month and 3-months-out interpretation of mock analytics?
Mock analytics interpretation changes fundamentally over the timeline to exam. Three months out — wide-angle interpretation. Look at subject-level patterns, total time management, broad topic gaps, conceptual frameworks; spend 60-70 percent of remaining study time on broad concept revision and 30-40 percent on weak topics. Tolerable to spend 1-2 hours on each weak topic with primary source revision. Six weeks out — narrow-angle interpretation. Drill down to specific topics; identify the top-10 weak topic cells contributing most to lost marks; spend 40-50 percent on these weak cells, 30 percent on consolidation, 20 percent on mocks. Last month — surgical interpretation. Stop broad revision; focus entirely on (1) Sure-and-wrong concept rewrites, (2) leech-card review, (3) top-5 weak topic cells, (4) mistake-bank flashcards. Do not start any new topic. Last week — confidence consolidation only. Review only the 100-150 highest-yield trap cards and known-confident cards; no new mocks; sleep, hydration, and mental rehearsal of the exam-day routine. Last 24 hours — only confidence cards; no new content. The neurocognitive reason is that new memories take 24-72 hours to consolidate; anything learned in the last week is unreliable under exam stress. Cohort data shows last-month strategic interpretation adds 15-30 marks vs students who keep doing more mocks.
This content is for educational purposes for NEET PG exam preparation. It is not a substitute for professional medical advice, diagnosis, or treatment. Clinical information has been reviewed by qualified medical professionals.
Written by: NEETPGAI Editorial Team
Reviewed by: Pending SME Review
Last reviewed: May 2026